Stock_Market_Real_Time_Data_Project
Real Time Stock Market Data Project
In this project, real time data streaming is simulated using python to understand how data is sent from producer to consumer. The purpose of this project is to understand working of kafka and try hands on exercises.
Here are the steps that I followed:
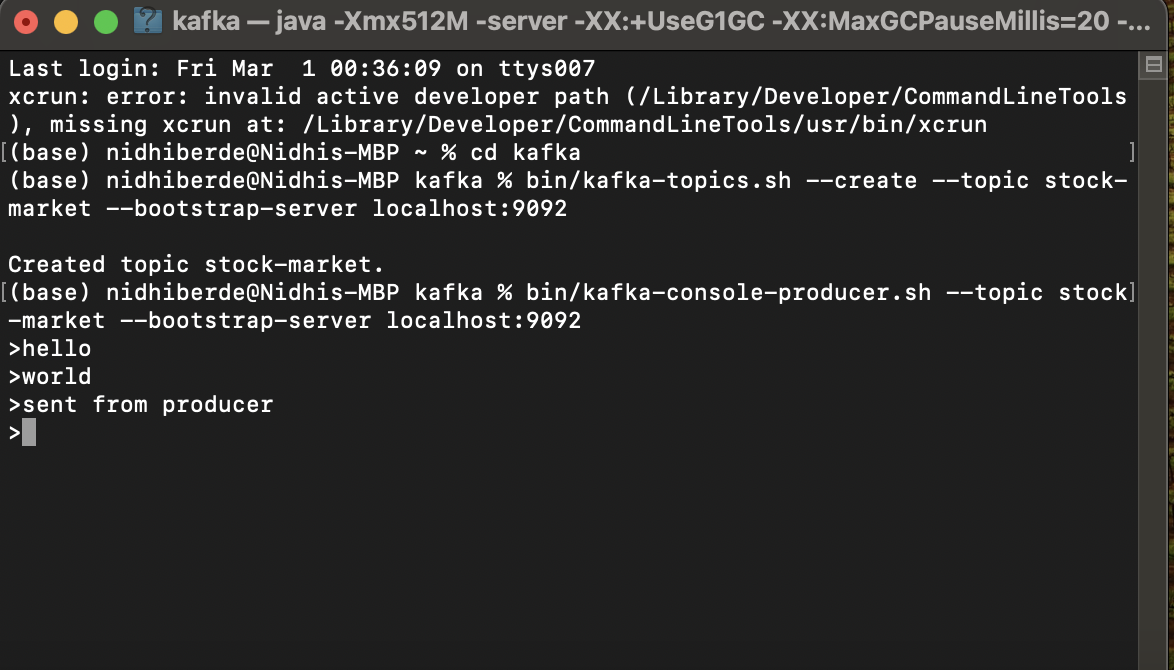
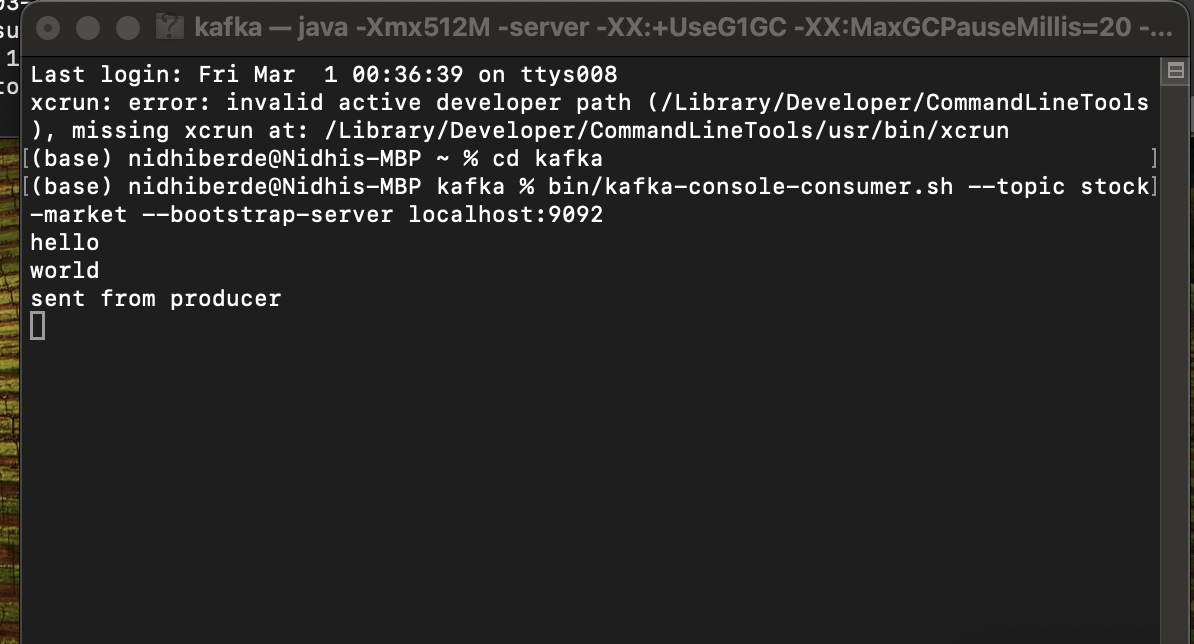
- Download Kafka on your local machine, start the zookeper, kafka server, create a topic, start the producer and consumer. ‘Kafka_Commands.txt’ has all of the necessary commands for this step.
- The data is currenltly in a csv format. However this step can be replaced by calling api of any source that allows to read real time stock data. To create a simulation of streaming, the data is consumed using a loop.
- After the data is read, using the loop, the data is sent through the producer to the consumer one by one. These steps can be found in ‘Producer.ipynb’ and ‘Consumer.ipynb’
- Create a S3 Bucket and IAM role with necessary admin and glue permissions.
- Python’s s3fs library is used to store the consumed json data into seperate files onto the s3 bucket.
- Create a glue crawler, attach the s3 bucket, choose a database and create a new table. Run this glue crawler.
- As the data is sent from the producer, it is consumed and sent to s3 bucket. The crawler then takes this json data and appends onto the table which was created.
- This table can now be queried through athena for further analyses.
Tools Used
- Python
- Kafka
- AWS S3, GLUE, ATHENA
Techniques
Data Cleaning, Kafka Concepts, ETL